
Built by a team of engineers and founders with backgrounds at







Our time-series foundation models provide
accurate insights and forecasting across industries.

Build modular AI agents for real-world prediction tasks fully customizable and deployable in minutes.
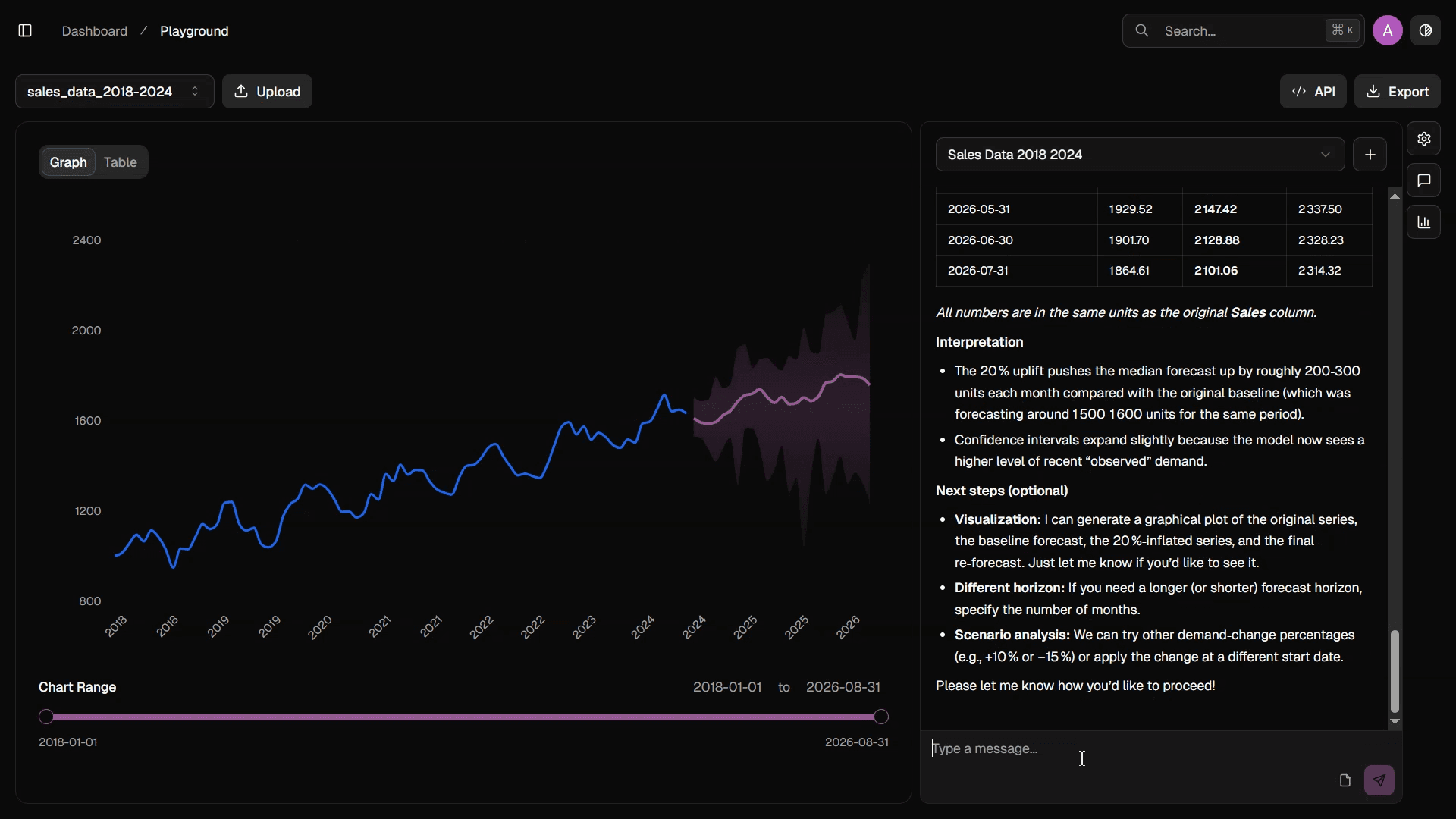
Long-horizon sales, pricing, macro indicators, seasonal signals.
Time-series foundation model
Detects regime shifts, structural changes, and long-term trends.
Used in pricing strategy, expansion planning, and risk analysis.
Market Forecasting
Detects regime shifts, macro trends, and long-horizon signals across time series.
LLM Forecasting Layer
Adds future-aware reasoning to language models.
Sales Forecasting
Generates short- and mid-term projections grounded in historical and behavioral data.
Demand Forecasting
Anticipates demand across supply chains with probabilistic confidence.
Working Across
Multiple Industries
Business Intelligence
Turn operational data into forward-looking decisions and strategic clarity.
Understand markets with deep competitive intelligence.
Anticipate churn before it happens.
Scale operations with optimized supply chains.
Financial Intelligence
Forecast risk, returns, and financial outcomes with precision and confidence.
Secure systems with fraud detection.
Optimize portfolios with algorithmic trading.
Predict risks with smarter assessment.
Healthcare Intelligence
Enable data-driven predictions that improve care, efficiency, and outcomes.
Discover drugs faster with AI models.
Treat patients with personalized medicine.
Save lives with epidemic forecasting.
Agricultural Intelligence
Optimize yields, resources, and resilience through predictive insights.
Grow yields with precision forecasts.
Protect crops with pest and soil monitoring.
Sustain farming with weather-adaptive insights.
Our platform brings you the best of artificial intelligence for enterprise decision making.
Day 1
Day 2
Day 3
Day 4
Day 5
Day 6
Day 7
Instant Prediction
No finetuning—just upload your data and get state-of-the-art results in minutes.

Database Integration
Connect directly to your favorite databases to pull and clean your data seamlessly.

Enterprise Ready
Secure, scalable infrastructure designed for mission-critical business applications and workflows.

